Ship LLM products that work. Every time.
Catch AI failures before production. Complete framework for production-grade LLM evaluation systems with zero guesswork.
What Makes EvalMaster Different
Four core capabilities that transform how you ship AI
Binary quality gates that actually work. Automated evaluation prevents AI failures from reaching production.
Pre-built framework and proven patterns. Set up comprehensive evaluation in hours, not weeks.
Traces, metrics, and observability out of the box. See exactly what's happening in your LLM pipeline.
Automate 80% of QA work. Deploy with confidence and iterate faster than ever before.
Production-Ready Framework
Complete system for defining, measuring, and automating AI evaluation
Faithfulness, Answer Relevancy, Tool Correctness, and more. Start evaluating on day one.
Deep dives into failure patterns. Turn failure modes into measurable, actionable criteria.
Quality gates that block bad deployments. Binary pass/fail decisions with full confidence.
Everything You Need to Know
Learn, explore real implementations, and reference comprehensive metrics

What "evals" actually are
TL;DR: Evals are production quality gates that catch AI failures before they break user experience.
Connect real conversations to automated quality checks
Turn failure patterns into measurable criteria
Gate deploys with confidence, fix what actually matters
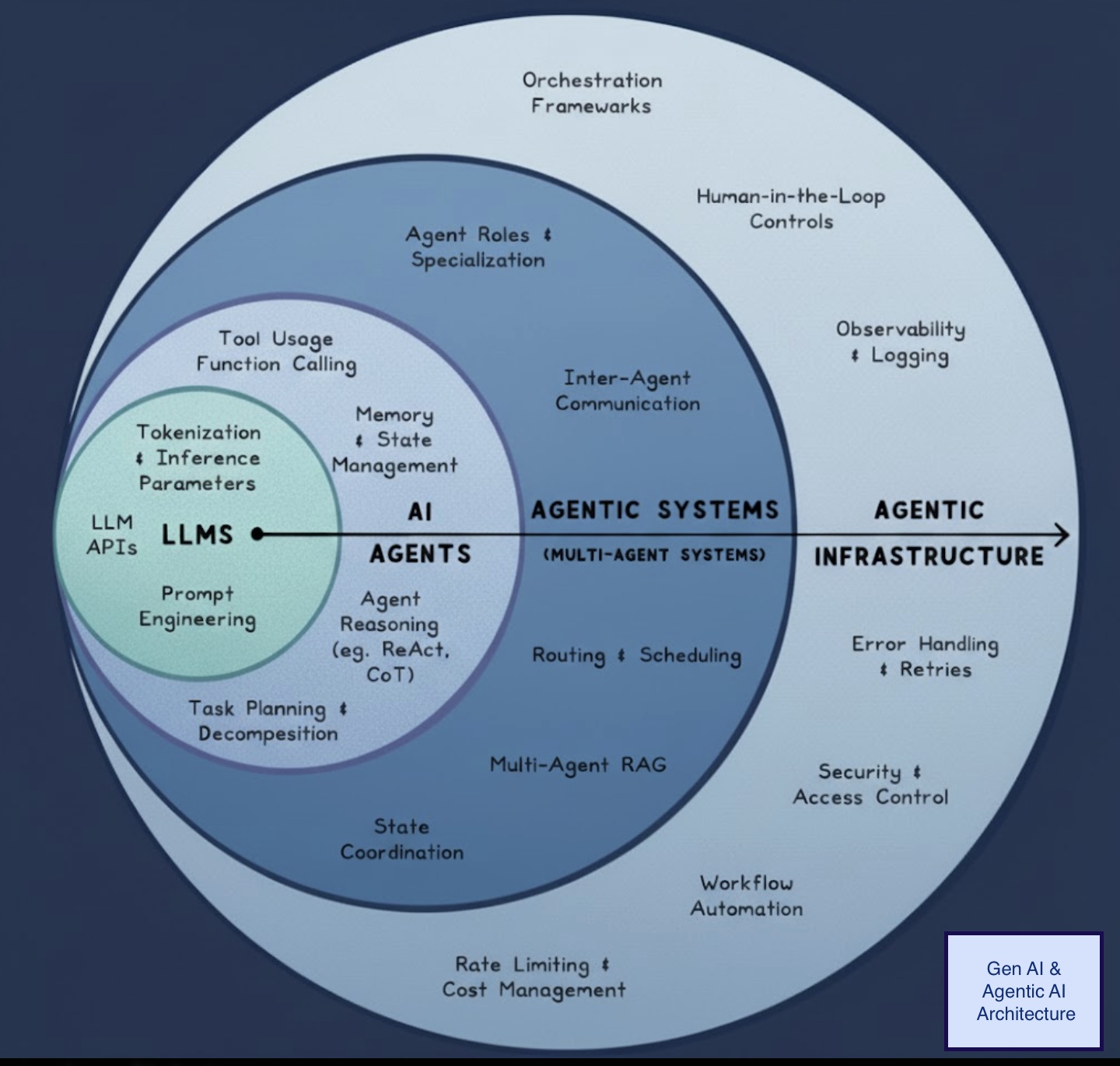
From LangChain to LangGraph
TL;DR: Use LangGraph for multi-step workflows; use LangChain inside individual steps for convenience.
Understand the four primitives: Graph, State, Nodes, and Edges
Learn when to use LangGraph vs. LCEL for your use case
Get a blueprint for building reliable agent workflows
From Chaos to Confidence
How organizations transform their AI evaluation in weeks, not months
Manual evaluation (slow, expensive, unreliable)
Days/weeks of setup and configuration
Expensive failures discovered in production
Zero visibility into what's happening
Automated evaluation gates (fast, reliable, scalable)
Hours to first eval with pre-built framework
Cost savings through gatekeeping and automation
Complete visibility with traces and metrics
Real Results from Our Customers
Reduction in QA time
Fewer production failures
Faster deployments
Cost savings
Real-World Results
See how leading companies transformed their AI evaluation
Reduced agent failures by 95% in production using comprehensive evaluation gates and automated quality checks.
Prevented hallucinations in retrieval-augmented generation systems with targeted evaluation and automated gates.
Caught temporal reasoning failures and edge cases before production, reducing post-launch debugging by 75%.
Get Started in 3 Simple Steps
From zero to production-ready evaluation in hours
Define Failure Patterns
Read 40-100 traces from your system. Write one note per failure. Group them into 4-7 actionable categories.
⏱️ 30 minutes
Setup Quality Gates
Choose your gates and thresholds. Use pre-built templates or customize. Set pass/fail criteria for each failure pattern.
⏱️ 1 hour
Deploy with Confidence
Monitor metrics in production with Langfuse. Gate deploys automatically. Alert on threshold violations.
⏱️ Ongoing
Ready to Ship Better AI?
Join thousands of engineers building reliable LLM systems. Get started free, no credit card required.