
Most AI agent guides hand you a tech stack and wish you luck. This one gives you a seven-phase system that takes you from problem definition to production, with human oversight and continuous improvement baked in from day one.
A framework by Nidhi Vichare
Seven phases take you from problem definition through architecture, knowledge ingestion, contextual memory, agentic reasoning, production scaling, and evaluation governance. Each phase builds on the last. Human oversight and continuous improvement are built in from day one.
System Overview
Ops, Trust & Memory Architecture
Click the diagram to explore full-screen
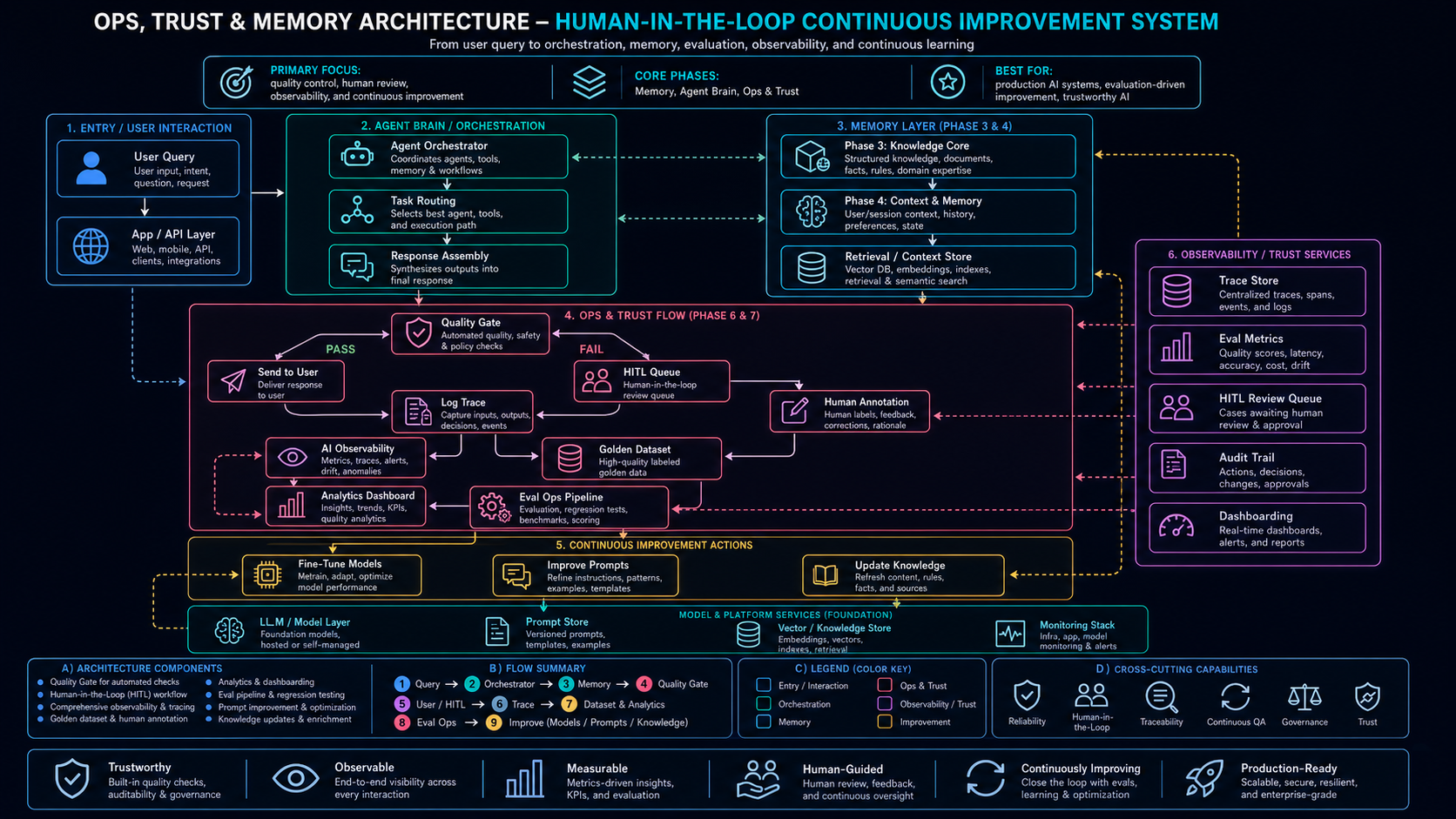
The Roadmap
Seven Phases of Agent Development
The Foundation Define the 'Why'
Establish business case and user-centric mission
1.1 Problem & Agent Value Proposition
- Problem Statement: What specific, high-cost process are you automating?
- Why an Agent?: Justify why this needs an agent vs. simple prompt or rule
- Value Hypothesis: By building an agent that can [ACTION], we will help [PERSONA] achieve [OUTCOME], resulting in [MEASURABLE_KPI]
1.2 Define Personas & Interaction Models
- Personas: Who is the user? (Support Engineer, Sales Analyst, Patient, etc.)
- Interaction Model: Human-to-Agent (H2A) vs. Agent-to-Agent (A2A)
- User Flows: Map the happy path and failure points
1.3 User Flows & Success Metrics
- Define KPIs: 'Reduce ticket resolution time by 30%'
- Map the happy path and key failure points
The Blueprint System Architecture
Design solution and select core tech stack
2.1 High-Level System Architecture
- Components: UI/Client, API Gateway, Orchestrator (MCP Server), Agent Services
- Tool/API Layer, Knowledge Base (Vector DB), Context & Memory Layer
- Operational DB (SQL for users, chat history, logs)
2.2 Data & Knowledge Architecture
- Operational DB (SQL): Schema for users, chat history, logs
- Knowledge Base (Vector): Schema for static RAG data (Phase 3)
- Context & Memory (Ledger/Vector): Schema for dynamic, user-specific data (Phase 4)
2.3 Select the AI Stack
- Performance: GPT-4o, Claude 3 Opus (high-stakes reasoning)
- Speed/Cost: Claude 3 Haiku, Llama 3 8B, Mistral-Nemo (routing)
- Privacy (Self-Hosted): Llama 3, Mistral
- Key Frameworks: LlamaIndex, LangChain/LangGraph, FastAPI
The Knowledge Core Static Memory
Build agent's public or domain memory (the 'R' in RAG)
3.1 Ingest
- Build data connectors for domain knowledge (Confluence, websites, technical manuals)
- Key Frameworks: LlamaIndex, Airbyte, Unstructured.io
3.2 Chunk - Decision Point
- Semantic (SemanticSplitterNodeParser): Groups by topic, excellent for prose
- Document-Aware (Markdown/Header): Best for structured docs, keeps sections intact
- Agentic Chunking: LLM decides how to chunk as it reads (Advanced)
3.3 Index & Feature Enrichment
- Vectorize: Convert chunks to embeddings (text-embedding-3-large, BGE)
- Add Rich Metadata: doc_id, section_title, created_by, date, security_level
- Vector Store: Load into Pinecone, Weaviate, or Postgres w/ pgvector
The Context & Memory Layer Personal Memory
Build persistent user-specific memory across all sessions and tools
4.1 Context Ingestion Framework (The 'Ears')
- Enterprise Connectors: Slack (messages), Email (IMAP/Graph API), ServiceNow, Jira (tickets), Confluence (docs)
- Application Connectors: Chat History, UI Clicks (navigation paths)
- Agent Connectors: Tool Outputs (results), Inter-agent Messages (A2A workflows)
4.2 Context Ledger (The 'Raw Facts')
- Purpose: Immutable, append-only log of all events (auditable ground truth)
- Technology: Event stream (Kafka) or time-series database
- Captures: timestamp, user_id, source, event_type, content_hash, metadata
4.3 Memory Synthesis Engine (The 'Processing')
- Purpose: Turn raw, noisy Ledger into clean, usable Memory (backend A2A process)
- Process: A 'Memory Agent' reads ledger, synthesizes it into insights
- Example: 'User has reported 3 VPN issues this month via Slack and ServiceNow'
4.4 Memory Store (The 'Retrievable Past')
- Purpose: Separate vector store for synthesized memories from 4.3
- Critical Metadata: user_id, topic, date_range, source_system (slack, email, etc.)
- This is the agent's 'personal' memory (distinct from Knowledge Core)
4.5 Contextual Governance & Privacy (The 'Gate')
- Purpose: Enforce configurable data access per user, per agent, per data source
- Context Policy Service: Before retrieval, check consent and permissions
- Example: 'Does user-123 consent to prescription history for billing questions?'
The Agentic Core Reasoning & Orchestration
Build agents using Static Knowledge + Personal Memory
5.1 The 'Brain' (Reasoning Loop)
- ReAct Pattern: Reason → Act → Observe → Repeat
- Super-charged Observe: Retrieves from BOTH Knowledge Core (Phase 3) AND Memory Store (Phase 4)
- LLM for reasoning + Tools for acting = Agent Loop
5.2 The 'Orchestrator' (Collaboration)
- MCP Server: Central hub managing state and routing tasks (H2A entrypoint)
- MCP Client(s): Individual agents as microservices registering their tools (A2A workers)
5.3 The 'Hands' (Tools)
- Tools are annotated Python functions
- CRITICAL NEW TOOL: retrieve_user_memory(query, sources=['all']) → checks Context Policy → queries Memory Store → returns memories
- Other tools: search_knowledge_base(), get_user_profile(), request_human_review()
The Production Stack Eval Ops & Scaling
Productize agent for scalability, reliability, continuous improvement
6.1 Deploy as a Service
- Containerize Agent Orchestrator (MCP Server) as microservice
- Containerize each Agent (MCP Client) as separate microservice
- Scale agents independently based on demand
6.2 Caching
- Implement semantic caching before costly agent runs
- Check if semantically similar query already answered
6.3 Eval Ops for Agents - Decision Point
- Prompt Engineering (Fastest): Fix bad prompts using eval data
- Fine-Tuning (Better): Use human annotation data to fine-tune model
- Quantizing (Smaller/Faster): Reduce precision for speed with minimal quality loss
- Feature Engineering: Add new valuable metadata to Knowledge Core and Memory Store
The Trust Layer Evaluation & Governance
Create human-in-the-loop system guaranteeing AI quality and reliability
7.1 Evaluation Methods - Decision Point
- LLM-as-a-Judge: Use powerful LLM (GPT-4o) with clear rubric to score answers
- Human Annotations (HITL): Build UI for experts to score/correct (ground truth)
- Deterministic Evals: Code-based checks (fast, free, limited to simple rules)
- NEW: Contextual Relevancy - Did agent use user history appropriately?
- NEW: Contextual Completeness - Did agent miss obvious user history it should use?
7.2 Hybrid Confidence Scoring (Quality Gating)
- Combine: Retrieval Score + LLM Self-Eval + LLM-as-Judge Score
- Gate: score > 0.9? → Send to user : FLAG and send to HITL queue
- NEVER send low-confidence answers to users
7.3 AI Observability (The Traces)
- Capture entire agent workflow: Query → Thoughts → Memories Retrieved → Knowledge Retrieved → Tools → Result
- Track: Cost, latency, tokens, which memories were used, which docs were retrieved
- Frameworks: Langfuse, Arize, Weights & Biases
Decision Architecture
Critical Decision Points
Make informed choices at each phase
Interaction Model
H2A (user gives task, agent completes) vs. A2A (agent triggers agent, fully automated)
LLM Selection
Performance (GPT-4o, Claude 3 Opus) | Speed (Haiku, Llama 3 8B) | Cost (Mistral-Nemo) | Self-Hosted (Llama 3, Mistral)
Chunking Strategy
Semantic (groups by topic, best for prose) | Document-Aware (structured docs) | Agentic (LLM decides, advanced)
Memory Architecture
Connectors (Slack, Email, ServiceNow, Jira) | Ledger (immutable event log) | Synthesis (Memory Agent) | Store (vector DB) | Governance (consent)
Orchestration Pattern
MCP Server (central orchestrator, H2A) | MCP Clients (agents as microservices, A2A) | retrieve_user_memory() as critical new tool
Eval Ops
Prompt Engineering (fastest) | Fine-Tuning (better, human annotations) | Feature Engineering (new metadata for Knowledge/Memory)
Evaluation Methods
LLM-as-Judge (fast, scalable) | Human Annotation (ground truth, expensive) | Deterministic (fast, free, simple). NEW: Contextual Relevancy & Completeness metrics
The Gate
Hybrid Confidence Scoring
Ensuring only high-confidence answers reach users
Generate Response + Score
COMPUTECombine: Retrieval Score + LLM Self-Eval + LLM-as-Judge Score
Quality Gate Decision
PASSIF score > 0.9 → Send to user
Flag Low Confidence
FAILIF score < 0.9 → FLAG and send to Human-in-the-Loop queue
Human Review
REVIEWExpert annotates and corrects, creating golden dataset
Key Principle
NEVER send low-confidence answers to users. Always gate with hybrid scoring + HITL. The cost of a wrong answer is always higher than the cost of a human review.
The Flywheel
Continuous Improvement Loop
How Evals Feed Back Into the System
Diagram Flow Guide
The Complete Flow. Step by Step
The Eval Ops Feedback Loop
Production Agent
Serves user queries with confidence scoring
Quality Gate
Route low-confidence to HITL, high to user
Log Traces
Capture full workflow: query, reasoning, tools, result
AI Observability
Langfuse/Arize: identify failures, cost, latency
Human Annotation (HITL)
Build golden dataset from expert corrections
Eval Ops Pipeline
Use insights to improve system
Continuous Improvement Actions
Under the Hood
How the Tech Stack Enables It
Ready to Build Production
AI Agents?
Use this framework with the open-source stack. Full control, full transparency, no lock-in.
Go deeper with the course
Master AI evals with hands-on projects, real case studies, and production-ready templates. From failure taxonomy to CI/CD quality gates.