The Problem
A user asked, "Can I expense a new coffee machine for my home office?" The retriever fetched General-Reimbursement-Policy-v4.pdf — a permissive policy document — but completely missed Reimbursement-Exclusion-List-v2.pdf which explicitly forbids kitchen appliances. The LLM answered "Yes," faithfully reflecting the incomplete context it received.
This is the most dangerous failure mode in RAG: the answer is faithful to the context but the context itself is incomplete. A faithfulness score of 0.95 masked a contextual recall of just 0.45. The system looked like it was working perfectly — until employees started filing invalid expense claims.
Impact
Partially correct but subtly wrong answers are more dangerous than obviously wrong ones. 12 policy violations filed before detection. Financial disputes with employees. Complete erosion of trust in the HR assistant for compliance-sensitive queries.
Why This Is Insidious
This is the most dangerous class of RAG failure: high faithfulness with incomplete context. The LLM did exactly what it was supposed to — it faithfully summarized the documents it received. The Faithfulness score was 95%. A naive eval system would have marked this as a passing response.
The root cause wasn't the generator — it was the retriever. The retriever found the permissive policy but completely missed the exclusion list. Without measuring Contextual Recall (did we find ALL the relevant documents?), you can't distinguish between a correct answer and a plausible-but-wrong one.
This pattern repeats across every domain: medical guidelines with contraindications in separate documents, legal contracts with amendments in different files, technical docs with deprecation notices in changelogs. If your retriever misses the exception, your generator will confidently give the wrong answer.
Real-World Analogy
A lawyer who reads the contract but not the amendment. Their legal analysis is technically correct based on what they read — but the amendment changes everything. Faithfulness doesn't help when the evidence is incomplete.
What Happened — Trace Walkthrough
User Query
"Can I get reimbursed for a coffee machine for my home office?"
Intent correctly identified: reimbursement eligibility check for home office equipment (coffee machine)
Found General-Reimbursement-Policy-v4.pdf (partial match). Ranked it top-1 based on keyword overlap with 'reimbursement' and 'office equipment'
Reimbursement-Exclusion-List-v2.pdf never retrieved. Poor metadata: no 'policy_type' tag, no relationship link to the general policy, low embedding similarity to query
LLM faithfully synthesized answer from retrieved context. Output: 'Yes, you can expense office equipment including coffee machines...' — correct given its input
Employee filed $200 expense claim for a kitchen appliance. HR rejected it citing exclusion list. Employee disputed, citing the AI assistant's answer as authority
Faithfulness
95%
High — misleadingly good
Contextual Recall
45%
Critical doc missing
Contextual Precision
60%
Wrong docs ranked top
What Would Have Caught This
A Contextual Recall metric running in CI would have flagged this immediately. The metric measures what fraction of the ground-truth answer can be attributed to the retrieved context. For policy queries, the expected answer must reference both the permissive policy and any exclusions — if the exclusion doc is absent, recall drops below the gate threshold.
# Contextual Recall gate — catches incomplete retrieval
def contextual_recall_gate(query, retrieved_docs, ground_truth_answer):
"""Score how much of the expected answer is supported by retrieved context."""
gt_statements = decompose_to_statements(ground_truth_answer)
supported = [s for s in gt_statements if is_attributable(s, retrieved_docs)]
recall = len(supported) / len(gt_statements)
if recall < 0.80: # gate threshold
missing = [s for s in gt_statements if s not in supported]
raise RecallGateFailure(
f"Contextual Recall {recall:.0%} < 80%. "
f"Missing statements: {missing}"
)
return recallIn this case, the ground-truth answer includes the statement "kitchen appliances are excluded from reimbursement." Since the exclusion doc was never retrieved, this statement has no attribution in context, and recall drops to 0.45 — well below the 0.80 gate. The CI pipeline fails with an actionable error pointing to the missing document.
Root Cause Analysis
Poor Metadata
The exclusion list had no 'policy_type' tag and no relationship metadata linking it to the general reimbursement policy. The retriever had no way to know these documents belong together.
No Semantic Linking
Related policy documents were not connected. The general policy and its exclusion list were indexed as independent documents with no cross-references or parent-child relationships.
No Recall Gate
Contextual Recall was not being measured or enforced. The team relied solely on Faithfulness, which scored high (0.95) because the LLM was faithful to its (incomplete) context.
The Fix — Three Defense Layers
Metadata Enrichment
Enhanced documents with policy type, section, and relationship metadata
# LlamaIndex parsing with enhanced metadata
from llama_index.core.node_parser import SemanticSplitterNodeParser
parser = SemanticSplitterNodeParser.from_defaults(buffer_size=3)
nodes = parser.get_nodes_from_documents(docs)
for node in nodes:
node.metadata.update({
"policy_type": "reimbursement",
"section": extract_section(node.text),
"related_docs": find_related_policies(node.text)
})Hybrid Retrieval with Reranking
Metadata-boosted retrieval ensures related exclusion documents surface alongside permissive policies
# Hybrid retrieval with metadata boosting
retriever = index.as_retriever(
similarity_top_k=10,
filters={"policy_type": "reimbursement"}
)
# Expand retrieval to include related docs
def expand_with_related(nodes):
expanded = list(nodes)
for node in nodes:
for related_id in node.metadata.get("related_docs", []):
related = index.get_node(related_id)
if related not in expanded:
expanded.append(related)
return expanded
# Apply reranking to boost exclusion documents
expanded_nodes = expand_with_related(initial_nodes)
reranked_nodes = reranker.rerank(expanded_nodes, query, top_k=5)Contextual Recall CI Gate
Automated evaluation gate that fails the pipeline when required documents are missing from context
# CI gate — catches missing context before deployment
def contextual_recall_gate(test_case, retrieved_nodes):
required_docs = test_case["expected_context_sources"]
found_docs = [n.metadata["doc_id"] for n in retrieved_nodes]
missing = [doc for doc in required_docs if doc not in found_docs]
if missing:
raise RecallGateFailure(
f"Missing required docs: {missing}. "
f"Recall: {len(found_docs)}/{len(required_docs)}"
)
recall = len(found_docs) / len(required_docs)
if recall < 0.80:
raise RecallGateFailure(f"Contextual Recall {recall:.0%} < 80%")
return recallReference Architectures
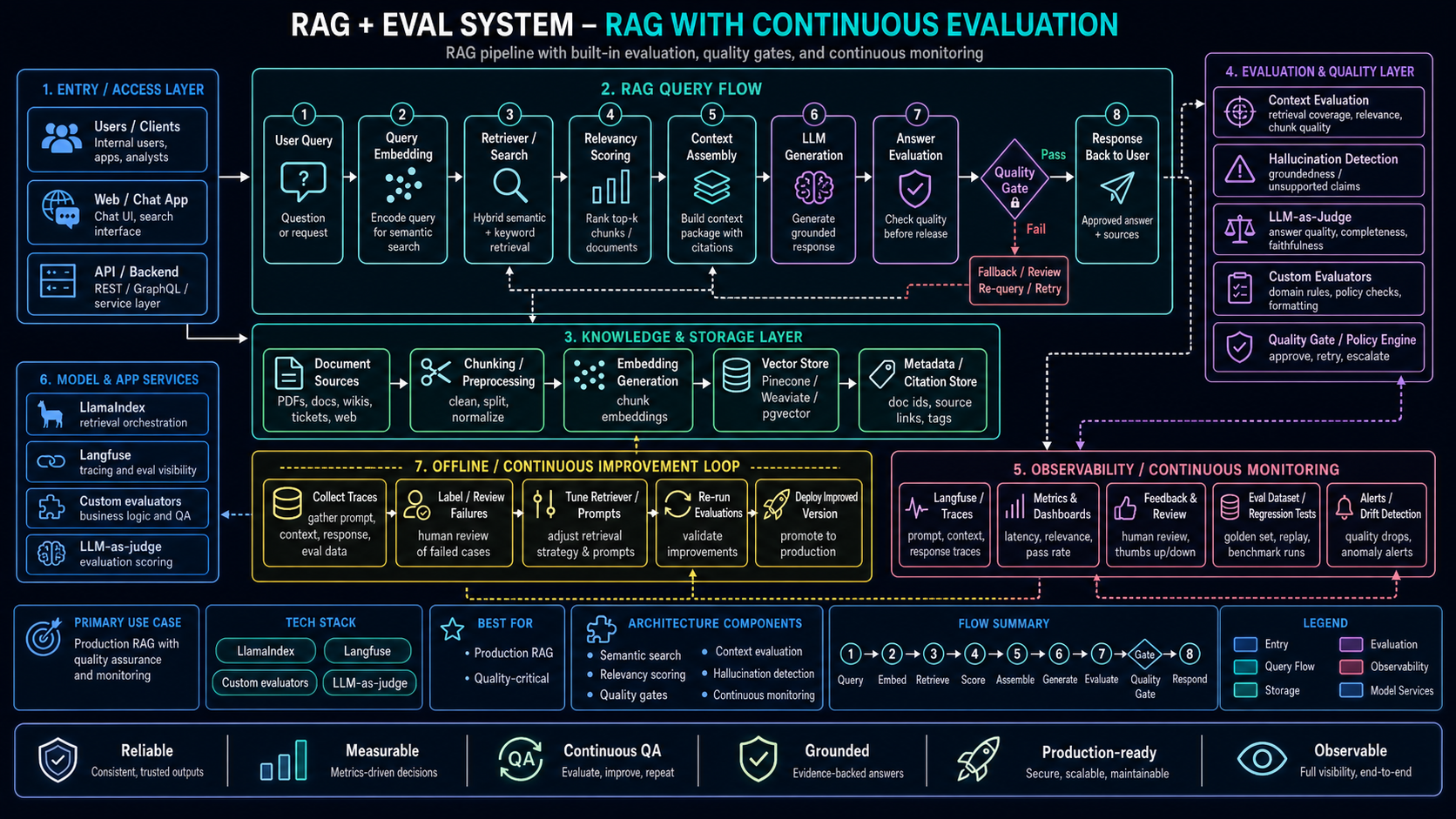
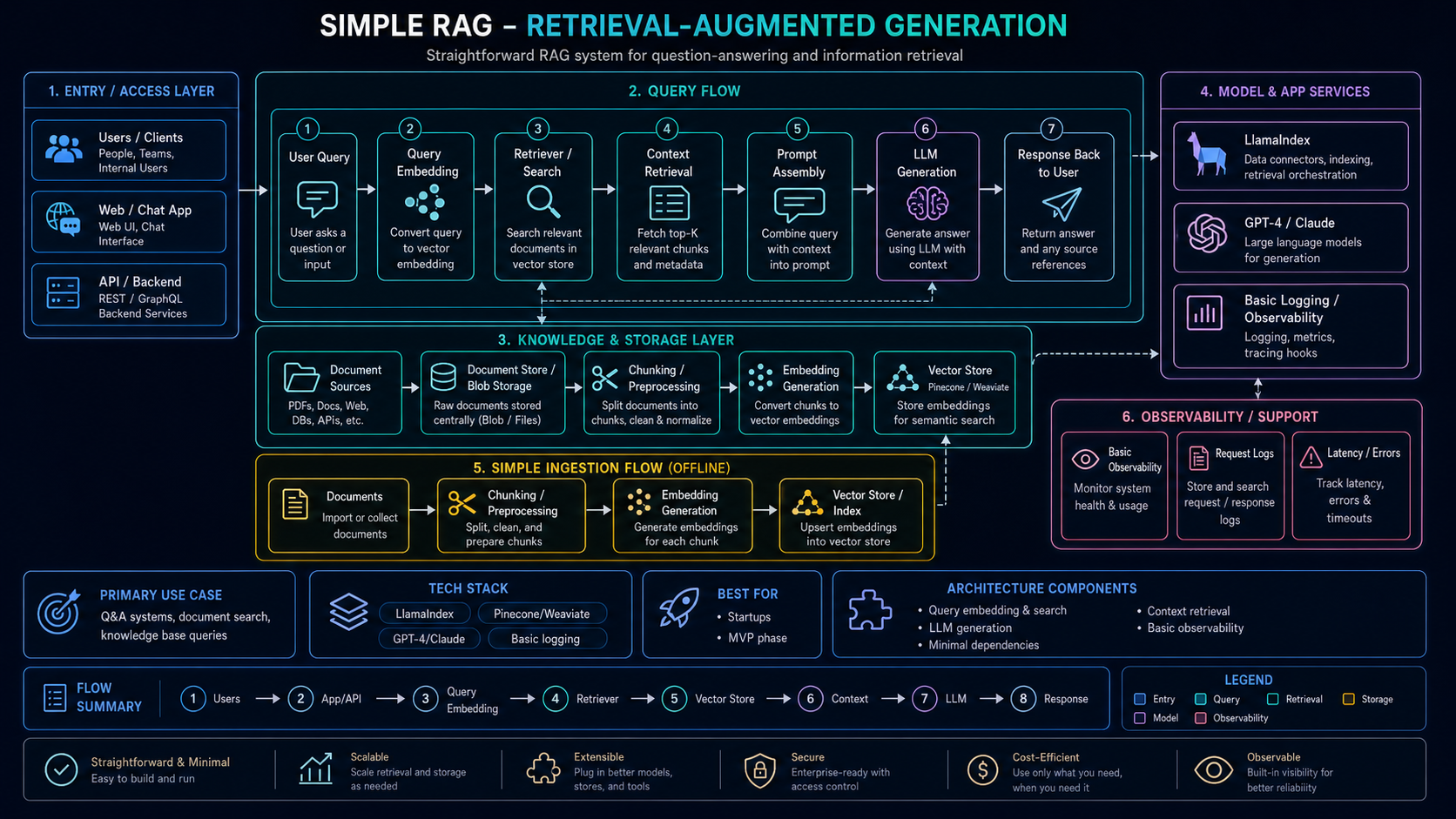
These diagrams show the RAG pipeline with quality gates and the eval system that catches context failures. Click to expand.
RAG + Eval System
Simple RAG Baseline
Results
Contextual Recall
Contextual Precision
Policy Violations
Outcome
CI/CD gate now fails with actionable error: "Retriever not finding exclusion list for reimbursement queries." Zero policy violations since deployment. The recall gate has caught 4 similar missing-context regressions in the 3 months since launch — each fixed before reaching production.
Key Lessons
Faithfulness Is Not Enough
A high faithfulness score only means the LLM is consistent with what it received. If the context is incomplete, faithfulness masks the real problem. Always pair it with Contextual Recall.
Contextual Recall Is Critical
For policy, compliance, and legal use cases, missing context is more dangerous than wrong context. Contextual Recall catches exactly this — measure it from Day 0.
Metadata Is Infrastructure
Enriching documents with policy type, section, and relationship metadata dramatically improves retrieval precision. Treat metadata enrichment as a first-class infrastructure investment, not an afterthought.
Automated Gates Catch Edge Cases
Manual testing never found this failure because testers checked faithfulness, not recall. Automated CI gates with golden test cases catch the subtle regressions that humans miss.
Prevention Checklist
Go deeper with the course
Master AI evals with hands-on projects, real case studies, and production-ready templates. From failure taxonomy to CI/CD quality gates.