The Problem
Production agents were calling non-existent tools or using malformed parameters, causing system crashes and complete task failures. The agent would confidently attempt to use SearchDatabase when only DatabaseQuery existed, or pass strings where integers were required.
No validation layer existed between agent tool calls and actual tool execution. The agent was hallucinating tool names and parameters with complete confidence — the worst kind of failure because it looked like it was working until it suddenly wasn't.
Impact
System downtime, failed user tasks, and complete loss of trust in the agent system. Emergency rollback required. 30% of all tool calls were invalid. Most tasks failed before completion.
Why This Is Hard to Catch
Tool hallucination is uniquely dangerous because it passes every surface-level check. The agent's reasoning is sound — it correctly identifies the user's intent, builds a reasonable plan, and explains its actions coherently. The failure only manifests at the execution layer, when the agent tries to call a tool that doesn't exist or passes parameters that don't match the schema.
Traditional unit tests don't catch this because they test tools in isolation, not the agent's ability to select and invoke them correctly. Integration tests help but can't cover the combinatorial explosion of possible tool + parameter combinations an LLM might generate. This is why eval-driven quality gates are essential — you need to measure tool correctness as a first-class metric, not just test it anecdotally.
Real-World Analogy
Imagine a new employee who writes perfect memos but keeps dialing wrong extension numbers when trying to reach other departments. Their writing is flawless, their reasoning is correct, but they can't actually execute because they're using the wrong phone system. That's tool hallucination — the reasoning is fine, the execution layer is broken.
What Happened — Trace Walkthrough
User Query
"Find all customers in California with orders over $1000"
Agent correctly identified: filter by state + filter by order amount
Agent called 'SearchDatabase' — this tool doesn't exist. Available: DatabaseQuery, FilterQuery, FormatResponse
Passed state='California' as string to a function expecting state_code (integer enum)
Tool 'SearchDatabase' not found → uncaught exception → system crash → user sees error
Tool Correctness
70%
30% of calls invalid
Task Completion
45%
Most tasks failed
System Uptime
82%
Frequent crashes
Root Cause Analysis
No Schema Validation
Tool calls were passed directly to execution without validating tool names or parameter types against the registered tool schema.
No Fallback Path
When a tool call failed, the error bubbled up uncaught. No circuit breaker, no retry with correction, no human handoff.
No Monitoring
Tool correctness wasn't being measured. The team had no visibility into how often tools were called incorrectly until production crashed.
The Fix — Three Defense Layers
Tool Schema Validation
Strict validation of tool names and parameters before execution
class ToolValidator:
def __init__(self, available_tools):
self.tools = {tool.name: tool.schema for tool in available_tools}
def validate_call(self, tool_name, parameters):
if tool_name not in self.tools:
raise ToolNotFoundError(f"Tool '{tool_name}' not available")
schema = self.tools[tool_name]
jsonschema.validate(parameters, schema) # raises on mismatch
return TrueTool Correctness Metric
Automated eval of tool usage against expected patterns — runs in CI
def evaluate_tool_correctness(trace, expected_tools):
called = [call.tool_name for call in trace.tool_calls]
expected = [t["name"] for t in expected_tools]
name_acc = len(set(called) & set(expected)) / len(expected)
param_acc = sum(1 for c, e in zip(trace.tool_calls, expected_tools)
if c.parameters == e["parameters"]) / len(expected_tools)
return min(name_acc, param_acc) # fail on eitherCircuit Breaker
Automatic fallback to human handoff when tool correctness drops below threshold
class ToolCircuitBreaker:
def __init__(self, failure_threshold=0.95):
self.threshold = failure_threshold
self.recent_scores = []
def record_score(self, score):
self.recent_scores.append(score)
if len(self.recent_scores) > 10:
self.recent_scores.pop(0)
avg = sum(self.recent_scores) / len(self.recent_scores)
if avg < self.threshold:
raise CircuitBreakerOpen("Tool correctness below threshold")Reference Architectures
These architecture patterns show where tool validation and circuit breakers fit in production agent systems. Click to expand.
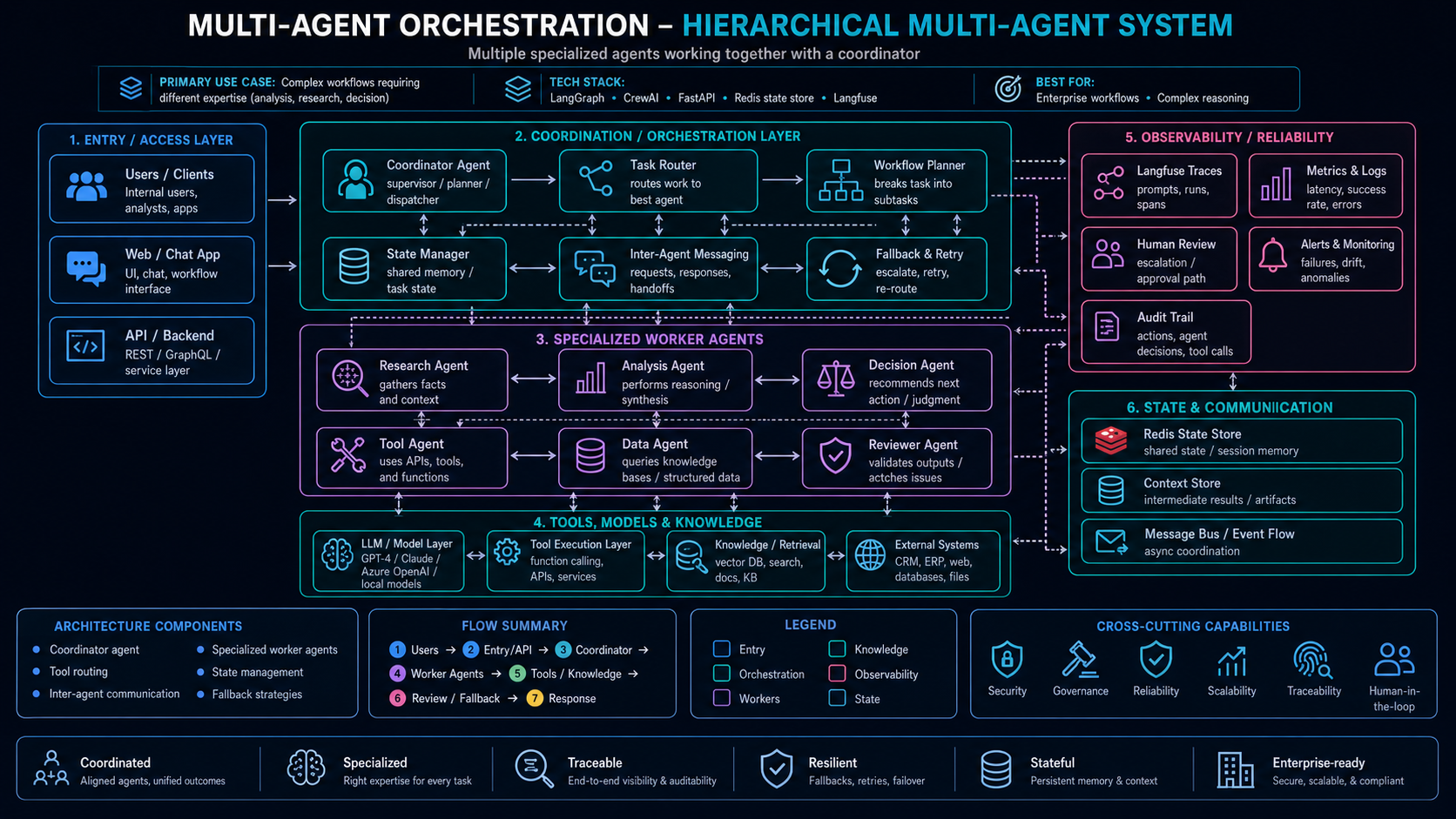
Multi-Agent Orchestration
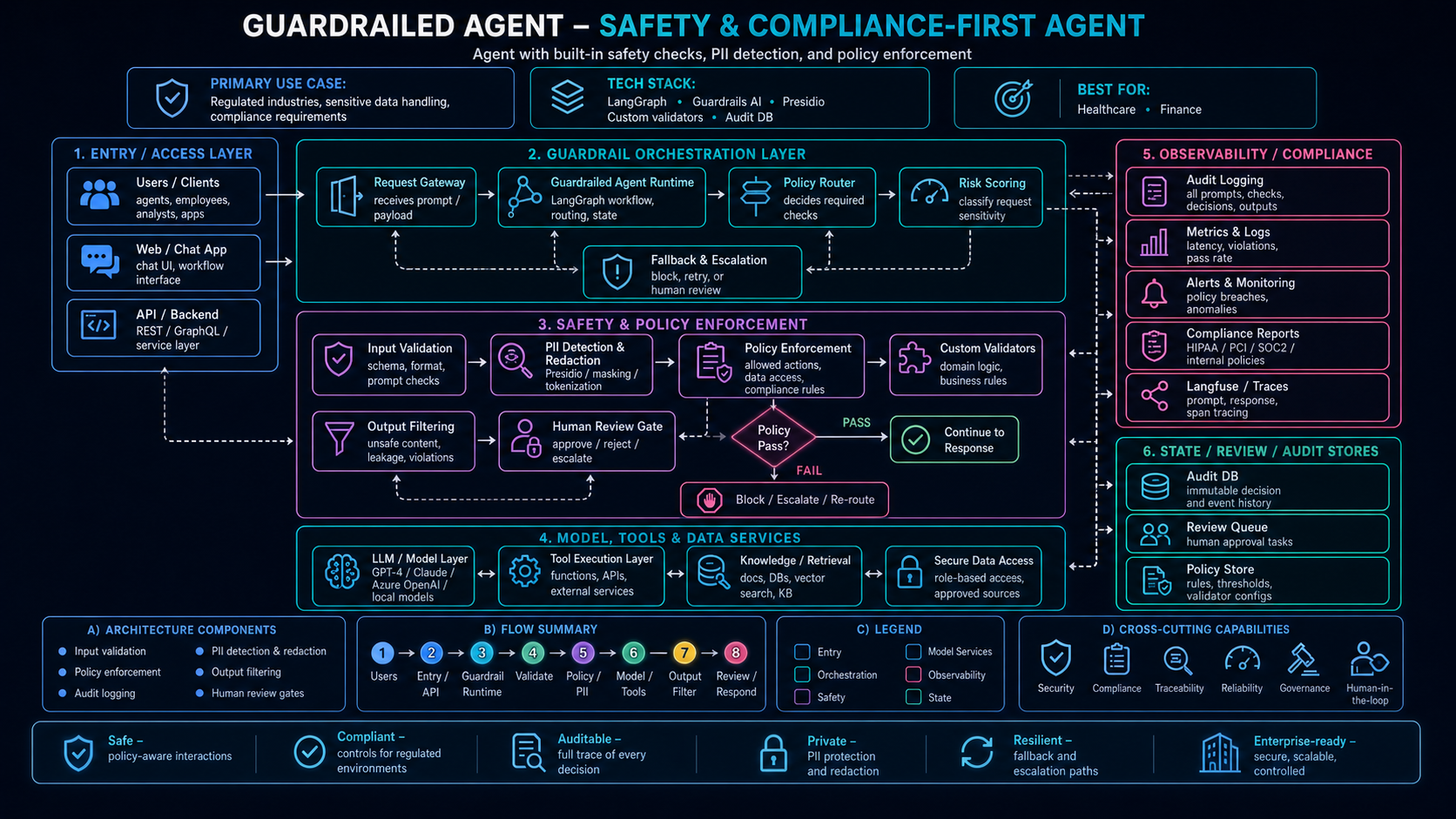
Guardrailed Agent Pattern
Results
Tool Correctness
Task Completion
System Uptime
Outcome
Zero tool hallucinations in production, with automatic fallback to human handoff when tool correctness drops. Circuit breaker has triggered 3 times in 6 months — each time preventing a cascade before users were affected.
Key Lessons
Validate Everything
Tool validation is non-negotiable for production agent systems. Every call must be checked against the schema before execution.
Build Circuit Breakers
Circuit breakers prevent cascading failures from tool errors. When correctness drops, fail gracefully to human handoff.
Set High Thresholds
Tool Correctness must have very high thresholds (≥95%). A 5% tool error rate means 1 in 20 user interactions fail.
Monitor the Chain
Agent reliability depends on the weakest link. If you're not measuring tool correctness, you're flying blind.
Prevention Checklist
Go deeper with the course
Master AI evals with hands-on projects, real case studies, and production-ready templates. From failure taxonomy to CI/CD quality gates.