The Problem
Users consistently received answers based on outdated PTO policies. The current policy (hr_policy_v3.pdf) existed in the knowledge base but was buried in a different section with poor metadata. Meanwhile, hr_policy_v2.pdf — outdated and superseded — kept ranking higher due to stronger keyword overlap and longer embedding history.
40% of policy queries returned outdated information. The retriever had no concept of time — it treated a document from 2022 identically to one from 2024. No temporal metadata, no version filtering, no staleness detection. The system was confidently serving yesterday's answers to today's questions.
Impact
Employee confusion, HR disputes, and potential legal compliance issues. 23 user complaints in one month. Trust in the AI system eroded rapidly. HR team had to manually review every AI-generated policy answer for two weeks while the fix was deployed.
Why Temporal Failures Are Silent Killers
Temporal failures are the hardest RAG bugs to catch because the outdated information was correct at some point. It passes faithfulness checks, it reads coherently, and it even sounds authoritative. The LLM has no way to know the document is stale — it treats all retrieved context as equally valid.
Unlike factual hallucination (where the model invents information), temporal errors serve real information that's simply no longer current. This makes them invisible to most eval metrics. Faithfulness? High — the answer matches the context. Relevancy? High — it's about the right topic. Only a temporal accuracy metric that checks document freshness catches this.
Every organization with evolving policies, pricing, procedures, or regulations faces this. HR policies change quarterly. Product pricing updates monthly. Compliance rules shift annually. Without temporal awareness in your RAG pipeline, your AI assistant becomes a confident time traveler — answering questions with yesterday's facts.
Real-World Analogy
A GPS that gives you directions based on last year's road map. The roads existed, the directions were technically correct at one point — but the highway exit was redesigned six months ago. The confidence of the directions makes the failure worse, not better.
What Happened — Trace Walkthrough
User Query
"What's our current PTO policy?"
Intent correctly identified: policy lookup for current PTO benefits. Keyword 'current' noted but not enforced as temporal filter
Retrieved hr_policy_v2.pdf (outdated, 2022). Ranked #1 due to stronger keyword match and more embedding training data from historical queries
hr_policy_v3.pdf (current, 2024) existed in index but ranked #8. No temporal metadata to boost it. No version filtering applied. No supersession chain recognized
LLM generated response based on v2 policy: '15 days PTO per year' — the old allocation. Current policy grants 20 days. No staleness warning emitted
Employee planned vacation based on 15-day limit. Discovered actual policy was 20 days only after talking to HR. Filed formal complaint about AI system reliability
Temporal Accuracy
25%
Most answers outdated
Contextual Precision
30%
Old docs ranked top
Contextual Recall
40%
Current policy missed
What Would Have Caught This
A Temporal Accuracy metric would have flagged this on the first test run. The metric checks whether the retrieved documents are temporally valid for the query — if a user asks for "current" policy and the retriever returns a superseded document, the score drops to zero regardless of semantic similarity.
# Temporal Accuracy gate — catches stale retrieval
def temporal_accuracy_gate(query, retrieved_docs, reference_date=None):
"""Score whether retrieved docs are temporally valid."""
reference_date = reference_date or datetime.now()
total, valid = len(retrieved_docs), 0
for doc in retrieved_docs:
effective = doc.metadata.get("effective_date")
expiry = doc.metadata.get("expiry_date")
superseded_by = doc.metadata.get("superseded_by")
if superseded_by:
continue # skip superseded docs
if effective and effective <= reference_date:
if not expiry or expiry >= reference_date:
valid += 1
accuracy = valid / total if total > 0 else 0
if accuracy < 0.90: # gate threshold
raise TemporalGateFailure(
f"Temporal Accuracy {accuracy:.0%} < 90%. "
f"Stale docs in retrieval set."
)
return accuracyIn this case, hr_policy_v2.pdf has a superseded_by: hr_policy_v3 flag and an expired expiry_date. The gate would have scored 0% temporal accuracy and blocked deployment with a clear error: "Stale docs in retrieval set for policy queries."
Root Cause Analysis
No Temporal Metadata
Documents lacked effective dates, expiry dates, and version numbers. The index treated a 2022 policy and a 2024 policy as equally valid. No way to distinguish current from superseded.
No Version Filtering
The retriever had no temporal filters. Even when documents had dates buried in their text, the retrieval pipeline never parsed or used them. Newer docs had no ranking advantage.
No Staleness Detection
No monitoring for temporal drift. The system had no way to detect when retrieved documents were outdated relative to what existed in the index. No alerts, no dashboards, no CI checks.
The Fix — Three Defense Layers
Temporal Metadata Enrichment
Every document tagged with version, effective dates, and supersession relationships
# Temporal metadata enrichment
from llama_index.core import Document
docs = [
Document(
text=policy_text,
metadata={
"doc_id": "hr_policy_v3",
"version": "3.2.1",
"effective_date": "2024-01-01",
"expiry_date": "2024-12-31",
"supersedes": ["hr_policy_v2", "hr_policy_v1"],
"superseded_by": None, # this is the current version
"section": "pto_policy",
"last_updated": "2024-01-15"
}
)
]Temporal Filtering + Reranking
Hard date filters exclude expired docs, temporal reranker boosts recent versions
# Hard temporal filter + soft temporal reranking
from datetime import datetime
current_date = datetime.now().isoformat()
# Step 1: Hard filter — only retrieve non-expired, non-superseded docs
retriever = index.as_retriever(
filters={
"effective_date": {"$lte": current_date},
"expiry_date": {"$gte": current_date},
"superseded_by": None
},
similarity_top_k=5
)
# Step 2: Soft rerank — boost more recent documents
class TemporalReranker:
def rerank(self, nodes, query):
for node in nodes:
days_old = (datetime.now() - node.metadata["last_updated"]).days
temporal_boost = max(0.1, 1.0 - (days_old / 365))
node.score *= temporal_boost
return sorted(nodes, key=lambda x: x.score, reverse=True)Staleness Detection + Alerts
Real-time monitoring catches temporal drift and alerts the content team before users are affected
class StalenessDetector:
"""Monitor retrieved docs for temporal drift."""
def __init__(self, max_age_days=90, alert_threshold=0.90):
self.max_age_days = max_age_days
self.alert_threshold = alert_threshold
def check(self, retrieved_docs):
stale = []
for doc in retrieved_docs:
age = (datetime.now() - doc.metadata["last_updated"]).days
if age > self.max_age_days:
stale.append(doc.metadata["doc_id"])
if doc.metadata.get("superseded_by"):
stale.append(doc.metadata["doc_id"])
freshness = 1 - (len(stale) / len(retrieved_docs))
if freshness < self.alert_threshold:
alert_content_team(
f"Staleness alert: {len(stale)}/{len(retrieved_docs)} "
f"docs outdated. IDs: {stale}"
)
return freshnessReference Architecture
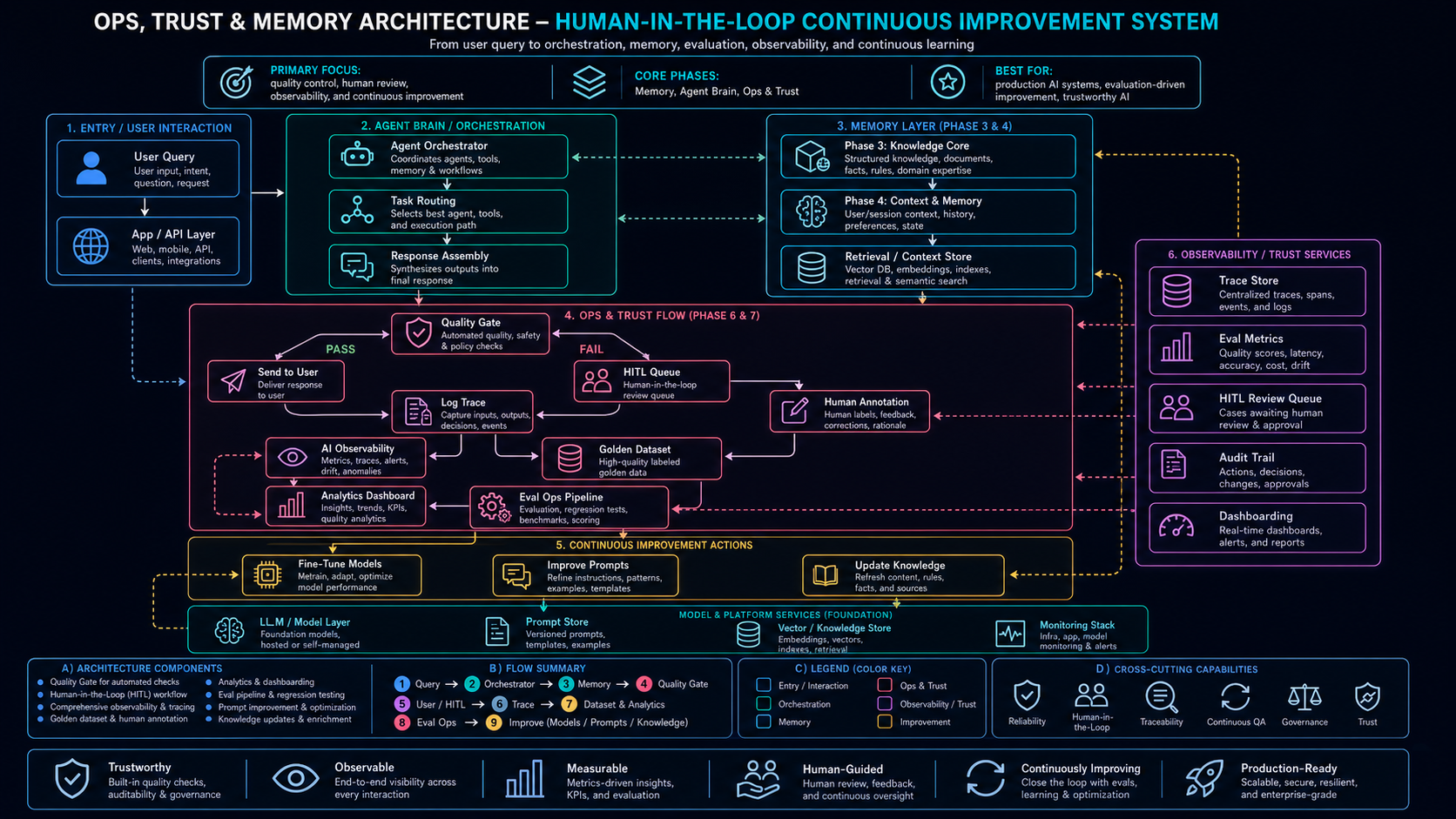
The continuous improvement loop catches temporal regressions through observability, human review, and automated re-evaluation. Click to expand.
Results
Temporal Accuracy
Contextual Precision
User Complaints
Outcome
Real-time alerts when outdated content is retrieved, with automatic escalation to the content team. Temporal accuracy jumped from 25% to 95%. User complaints dropped from 23/month to 1/month. The staleness detector has caught 6 newly-superseded documents within hours of upload — before any user query hit them.
Key Lessons
Time Is a First-Class Dimension
Temporal metadata is not optional for any system that serves time-sensitive information. Effective dates, expiry dates, and supersession chains must be indexed alongside content.
Hard Filters Before Soft Ranking
Temporal reranking alone is not enough — outdated documents can still score high on semantic similarity. Hard filters must exclude expired and superseded docs before ranking begins.
Version Control for Knowledge Bases
Knowledge bases need the same version discipline as code. Every document should have a version, a supersession chain, and a clear 'current' flag. Treat your KB like a Git repo.
Monitor Temporal Drift Continuously
Staleness creeps in silently. Automated monitoring catches temporal regressions before users do. Set up alerts for freshness drops and review them weekly.
Prevention Checklist
Go deeper with the course
Master AI evals with hands-on projects, real case studies, and production-ready templates. From failure taxonomy to CI/CD quality gates.